

Mobile Robotic Applications and Challenges
Mobile robots are being increasingly used for different applications, e.g., warehousing and manufacturing industries. Having accurate autonomous vehicle state estimation and control is pivotal. To meet these needs, it’s important to have path tracking algorithms that can:
- Satisfy the different scenarios in warehousing and manufacturing applications, e.g., vehicle speeds, obstacle avoidance maneuvers.
- Be implemented on physical hardware and tested.
Path tracking for mobile robots and Self-Driving vehicles has its own set of challenges such as:
- Coupling between longitudinal and lateral dynamics
- Nonlinear vehicle dynamics
- Uncertain vehicle parameters
- Implementation of algorithms on hardware
Model-based control is very effective for path following applications, but they depend on having an accurate model of the vehicle and this can be challenging in practice where disturbances can affect tracking performance, and unexpected changes or handling complex environment are difficult to consider. Using Artificial Intelligence (AI) techniques has the potential to address these challenges. Hence, the development and assessment of AI-based path-tracking solutions is currently an active field of research and requires reliable experimental platforms for their testing beyond simulations.
Challenge
How can we address these challenges?
Dr. Montanaro, senior lecturer in autonomous systems and control engineering at University of Surrey, and his team, Surrey for the Control of Smart Multi-agent systems Operating autonomously and Synergistically (Su-COSMOS), explored various path tracking methods, including sophisticated AI and neural-network based control solutions. Specifically, they developed and tested a novel AI technique leveraging Deep Reinforcement Learning (DRL) framework for path following applications [1]. In their formulation, the training process of the neural network is also informed by the decisions (vehicle steering) generated by an expert demonstrator to accelerate learning and improve the handling of new environments and paths to follow.
Deep Reinforcement Learning (DRL)
The architecture of the DRL strategy used by Dr. Montanaro, and his team is shown in Figure 1. The controller, or agent, is a neural network that applies at each sampling time an action to the environment. During training, the objective is to complete the path and maximize a reward function. The environment is the QCar equipped with a cruise control to regulate the speed, the action is the steering angle rate of variation (i.e., the derivative of the steering angle), and the observation is the path tracking error vector, consisting of the lateral error Δy and its derivative dΔy/dt and the heading error Δψ and its derivative Δr.

The agent was trained in simulation using an actor-critic deep deterministic policy gradient (DDPG) algorithm with a dynamic model they developed for the QCar.
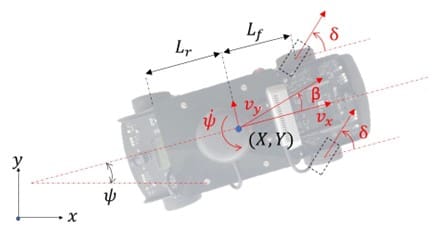
The parameters of the Quanser QCar were experimentally identified using a two-stage Least-Square method. This ensured the QCar model used to train the agent was accurate. The QCar coordinates and parameters are shown in Figure 2.
The reward function is used by the learning scheme to train the neural network of the agent which is then deployed on the actual QCar. Selecting a reward function is key to ensure the neural network modelling the agent is trained successfully and in a timely fashion.

Dr. Montanaro and his colleagues used the following reward function for each sampling time k:
r_k = r_y_k + r_Ψ_k + r_δ_k + r_ed_k
- The first component, r_y_k, considers the lateral error, the second component, r_Ψ_k, is for the heading error, and the third component, r_δ_k, is a penalty on the control action (i.e., derivative of steering angle). The rewards r_y_k and r_Ψ_k increase when the corresponding errors decrease, while the penalty r_δ_k is an increasing function of the control action.
- The expert demonstrator (ed) reward, r_ed_k, is a measure of the mismatch between the control action generated by the agent and that provided by a linear quadratic (LQ) path following regulator which was designed using the model described above.
- The learning scheme aims to maximize the cumulative reward over the episodes.
Solution
Expert Demonstrator – The Game Changer
The reward based on the expert demonstrator imposes a penalty when there is discrepancy between the steering angle commanded by the agent actual environment and the steering angle from the expert demonstrator in simulation. This helps decrease the training time by reducing the amount of exploration required and obtains a more robust solution by mitigating the simulation-to-reality gap. This is when a trained agent in simulation does not perform well in reality due to the environment being different or having difficulty handling paths that were used in the training.
Result
The experimental analysis has been conducted in the Su-COSMOS lab at the University of Surrey (see also Figure 3)
|
|
|


Figure 3: Experimental setup available within the Su-COSMOS lab at the University of Surrey (a) base station and (b) track with the QCars
The two main objectives were to find out:
- How well the trained agent in simulation performs on an actual path.
- The effectiveness of the expert demonstrator (ed) on the tracking performance.
For (1), the authors compared the path tracking performance obtained with the DRL solution (purple line) with three strategies:
- FF+FB: Feed-forward feedback controller (blue line)
- LQcm: an LQ controller with feedforward action computed to have zero lateral error in steady state conditions for the nominal model of the QCar (yellow line)
- LQed: the LQ controller used within the DRL scheme as an expert demonstrator (red line)
The tracking results when avoiding an obstacle is a C-shape path and shown in Figure 4 and Figure 5
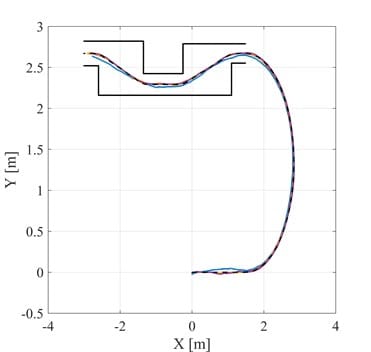
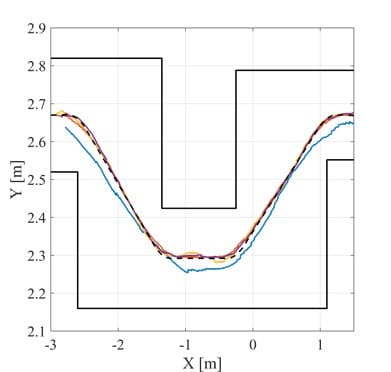
The reference path is the black dotted line. As shown, the path tracking performance of the feedforward feedback controller (FF-FB) is not as effective as the DRL algorithm. Moreover, the DRL algorithm also outperforms the LQ strategy used as expert demonstrator.
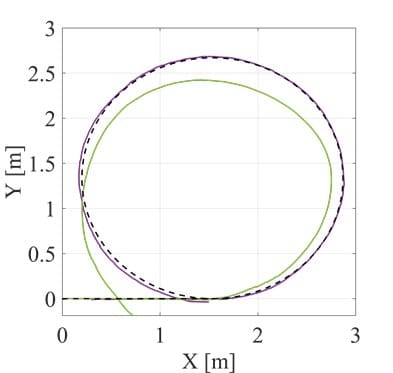
Figure 6 compares the path tracking between two DRL solutions, i.e., the one trained including an expert demonstrator within the formulation (purple line) and one obtained when the reward related to the expert demonstrator is removed from the formulation (green line). The selected path is a circular shape not used during the training. As shown, the DRL using the expert demonstrator has less lateral error. Using the expert demonstrator in the reward function can be a key factor when training an agent for path tracking tasks in reality. It mitigates the simulation-to-reality gap that is a drawback in some AI techniques.
For More Information
The You’re on the right path – Approaches to rapid prototyping and validation of advanced path-tracking solutions YOUser Webinar recording that Prof. Montanaro hosted is available on our website for on-demand viewing.
Other webinars that show how to use AI and other tools with Quanser systems are available for viewing as well.
For additional information, please contact us at info@quanser.com.
References
[1] C. Caponio, P. Stano , R. Carli, I. Olivieri , D. Ragone, A. Sorniotti, P. Gruber, U. Montanaro, Modelling, Positioning, and Deep Reinforcement Learning Path Following Control of Scaled Robotic Vehicles: Design and Experimental Validation, accepted for publication in IEEE Transactions on Automation Science and Engineering
Dr. Umberto Mantanaro
Umberto Montanaro received the Laurea degree (equivalent to an M.Sc.) in Computer Science Engineering (Hons.), cum laude, with a specialization in automation and control from the University of Naples Federico II, Naples, Italy, in 2005. He received a Ph.D. in Control Engineering in 2009 and a Ph.D. in Mechanical Engineering in 2016, both from the University of Naples Federico II. He is currently a Senior Lecturer in control engineering and autonomous systems at the University of Surrey, Guildford, UK. He is the director of the Surrey team for the Control of Smart Multi-agent Systems Operating Autonomously and Synergistically (Su-COSMOS). His research has resulted in more than 90 scientific articles published in peer-reviewed international journals and conferences. His research interests range from control theory to control applications, including adaptive control, optimal control, control of mechatronic systems, automotive systems, and coordination of networked autonomous systems.


